What the Tech!
Welcome to What the Tech!, a space where our Creative Technologist James Pollock shares updates that have piqued his interest in the world of tech.
Gaussian Splatting for Nuke, Houdini, After Effects and Unreal!
Last month I mentioned how Gaussian Splatting (aka 3DGS) was starting to see growing support in industry standard software, and since then there’s been a few updates to software and plugins that I thought I’d shout about.
First up is GSOPs (Gaussian Splatting Operators) 2.0, bringing support for Gaussian Splatting to Houdini. We’re big fans of Houdini at Lux Aeterna, having used it to create incredible shots for projects like Our Universe and Secrets of the Neanderthals, so we’re really excited to see what we can do with gaussian splats in the software now that GSOPs 2.0 is licensed under Houdini Commercial.
Next we have an update to PostShot. Version 0.5 brings 3DGS sequence support, which means if you can capture volumetric video, you now have a way to work with it in PostShot. PostShot also has plugin support with After Effects and Unreal, which opens up some really exciting opportunities for using volumetric video in VFX compositing or virtual production processes.
Speaking of compositing, Irrealix have recently revealed their 3DGS plugin for Nuke. The plugin gives Nuke users a range of useful tools for working with 3DGS, including colour correction, cropping and animation. Nuke is another key piece of our VFX pipeline, so we’ll be digging into how we might be able to make use of this new plugin.
Between all these demo videos, there’s a lot of really exciting and inspiring use cases on display. I hope to share some of our experiments with 3DGS soon!
Is Convex Splatting the New Gaussian Splatting?
By now you’ve probably heard of Gaussian Splatting, the fast and detailed method of rendering 3D scenes using many small, soft ellipsoids called “Gaussians”. Gaussian Splatting (also known as 3DGS) is often used in reconstructing 3D scenes from photographs and video, and is excellent at representing view-dependent qualities such as specularity. We’ve covered developments in this technology a few times on the blog, as well as its potential use within the VFX industry.

An example of 3DGS, in the zoomed in image we can see the individual Gaussians
Well, now there’s a whole kind of splatting on the scene! ‘Convex Splatting’ uses smooth convex shapes to build its representation of 3D geometry and radiance fields. The researchers behind this approach claim that Convex Splatting improves on what 3DGS offers by being more capable of tackling sharp edges and fine details while maintaining high rendering speeds. The project page has a detailed breakdown of the approach and is full of examples of what Convex Splatting can achieve. Be sure to check out their presentation video too.
The last 18 months or so have seen a lot of interest in 3DGS, with developers working to build support into various software such as Unreal, Houdini and Maya, as well as develop services that can build 3DGS based on phone photos. The question is; will Convex Splatting see the same levels of interest and ultimately replace 3DGS in the same way that 3DGS replaced Neural Radiance Fields in many applications? In any case, it’s great to see this emerging area of computer graphics continue to evolve.
Entagma’s Machine Learning
Time to drill into one of my favourite DCC's, a major piece of the puzzle here at Lux Aeterna, Houdini. One of the more exciting developments in VFX for me, more than AI in general is machine learning in Houdini. To help with this we have the great and wonderful team at Entagma.
Houdini has always been a great application, leveraging proceduralism and the ability to crunch huge amounts of data but adding machine learning has the potential to take things to another level. Some of this is already implemented in Houdini with machine learning algorithms for muscle weight painting a feature available now but by giving artists the power of ML right next to VEX, simulation, the new Copernicus context and the aforementioned proceduralism we could be about to see rapid technological change as artists innovate across the VFX industry.

Visualisation of latent space in Houdini
Entagma’s Machine Learning 101 course is a great starting point for anyone looking to dive into this space. It’s not about turning VFX artists into coders; it’s about showing how accessible these tools really are. Whether you’re curious about training a basic model or integrating machine learning into your existing Houdini projects, there’s a lot of potential to explore.
Image HDR Reconstruction
I’ve been keeping an eye out for innovations and interesting work outside of the generative AI space recently, as I think there has been a lot of important machine learning stuff going on that hasn’t necessarily cut through the gen AI noise, and some of this work may well form part of the tools that we use in the near future.
One example of this is the Computational Photography Lab at Simon Fraser University’s work on reconstructing high dynamic range (HDR) images from low dynamic range (LDR).
LDR images have limited contrast between the darkest and brightest areas, often appearing flat with less detail in shadows and highlights. HDR images have a wider range of contrast that preserves more detail in both the shadows and highlights, making them look more vibrant and true to life. HDR imagery is also more flexible and useful for visual effects, particularly where work may need to meet HDR broadcast specifications.

The researchers at the Computational Photography Lab took on the challenge of taking LDR images and expanding out their dynamic range, filling in the missing information required to create a HDR image. What makes their approach work is that they do this breaking the task down into two separate sub-tasks: extending the dynamic range and recovering lost colour details. Their video does a great job of explaining this process - I’ll add that the Lab is doing great work with their presentation videos, they’re a cut above the usual!
If you get the sense that the approach of breaking down images this way could be used to tackle other tricky image tasks, you’d be right, the Computational Photography Lab have also looked at using a similar approach for relighting flash photography. It’s also similar to how many VFX compositing tasks are approached, arbitrary output variables (AOVs) are renders split up into passes such as albedo, specular and lighting. This is part of the reason why this “decomposition” work is very compelling in the VFX space, it could help make the process of working with video and images much more flexible.
Generative Extend in Premiere Pro (beta)
A while back Adobe announced that new AI-powered features would be coming to their video editing software, Premiere Pro, including Generative Extend. Well, that feature has now arrived in the latest beta version of Premiere, but what does it do? Adobe’s demo video does a great job of showcasing how it works:
So, basically, Generative Extend lets you pull the end of your clip beyond the length of the actual footage, prompting Adobe’s generative video model to continue the rest of the clip, creating whole new content based on the previous frames. Sounds similar to the image-to-video feature we tried with Runway a few weeks ago, but I was intrigued to see how much looking to the previous frames helps generate more consistent and realistic extension.
Okay, so here’s the test I gave Generative Extend. A video of a tram passing in front of a bookshop I downloaded from Pexels. Now let's imagine that I wanted to use this shot but I wanted to start on the bookshop, have the tram pass, and end on the bookshop. Right now, the tram is already passing by at the start of the clip, so what if I use Generative Extend to try and give me the moments before the tram enters the shot.
Interesting! I’ve put a green border around the generated section of the video. It’s able to get some of the information about what’s in that space when the tram’s not there, but a lot of stuff is just missing or wrong. To be honest, I set out to try and push Generative Expand to its limits, and thought this might be something it would struggle with, so I’m not disappointed at all! I was trying to discover if it takes information from the whole video or just the last frame, and it definitely does!
It looks like it interprets the reflection of a truck as being a truck on the other side of the tram. Maybe the generated shop front looks greenish and odd because it's reconstructing from what it sees through the window, rather than from later in the video. I'll have to do another test!
Gaussian Haircuts?
Anyone who has ever tried to do volumetric capture of people will tell you that capturing hair can be a real pain. A head of hair is a complex, dynamic thing made up of thousands of strands (for most people anyway!), and volumetric capture methods can result in rendering the hair as a static, poorly defined blob - a bit like a Lego haircut!
What the researchers behind Gaussian Haircut have developed is a method for reconstructing hair as a collection of strands of gaussians. We've covered gaussians and gaussian splatting a few times before, but the basic idea is that a gaussian is a 2D ellipsoid that can represent a small part of 3D object, and a bit like pixels, if you have enough of them you can show the full object. Gaussians can also change colour based on what angle they're viewed, which means they can also capture things like reflections - very useful for glossy hair.

So a big part of what makes Gaussian Haircut so great is that it structures the hair gaussians so they align with strands, so the strand of hair is actually a strand of gaussians. Another cool thing is that this process results in outputs that can be taken into traditional 3D software and used for VFX and games. There's a demo on the project site where a hairstyle captured this way has been transplanted onto a metahuman character in Unreal Engine, and it looks great!
Editing Images in 3D
Often, we get asked to find ways to animate and dimensionalise images. This is usually for historical documentaries that want to bring archive imagery to life. Well, researchers at Jagiellonian University and University of Cambridge have devised MiraGe, their method for editing and animating 2D images by turning, making them 3D.
The process takes an element within an image and interprets it in 3D using Gaussian Splatting (check out some of our explorations into GS in previous posts), this allows the user to manipulate this element in 3D, then the process applies the edited area back onto the 2D image. What I love about this process is how crazy it sounds to turn an image into a 3D representation so you can do things like simulate physics, and then turn it back into an image.

The other interesting thing about this approach is that, unlike the process we used for last's week experiment, this process doesn't use any generative AI (although I think some of their examples use generated 2D images as a starting point).
Gen-3: Experimenting with Reanimation
On Wednesday evening I was thinking about Gen-3’s image-to-video feature, that’s the one that can create a video from a single image. Then I had this strange idea; what if you used it to bring taxidermied animals back to life?
So yesterday afternoon, I headed off to the museum’s taxidermy section and started snapping away with my phone:

Back at the studio, I uploaded the images and ran them through Gen-3 with prompts such as “steady camera shot of live animals behind glass, looking around” and... it worked! Some of the results were a bit funky but after a few reattempts I managed to get a selection of videos together. I sent them onto Rob and he put this together:
Wild, right? It’s crazy we were able to turn this around so quickly, I guess that’s one of the superpowers of generative AI. The quality is a little lacking, Gen-3 only produces videos at 1280x768 currently and there’s “AI weirdness” even in the best videos, but it got the concept across well and was a fun experiment!
Runway Gen-3
A few weeks ago we looked at Runway's new Gen-3 video generation model and how it can take a single image and use it as the start or end frame of a generated video. Since then, they've unveiled a new feature for 'video to video' generation, which generates video guided by another video.
To test this process, I rendered out a simple previz-style shot where the camera flies down from above a city street and comes to rest on a car under a bridge.
I uploaded the shot to Runway and prompted for "Dramatic cinematography, camera swoops down over London and onto a classic black sedan parked under a bridge, cool greenish bluish tones", and this is what Gen-3 generated:
Pretty interesting! Obviously the quality isn't there as a final output, but it does capture some of the vibe of what a final shot could look like. The question is, how helpful is that for previz, storyboarding and beyond?
Film and TV studio Lionsgate appear to see potential in Runway's offering, they've signed a deal with the AI company to train a bespoke model on their own content and claim it will save millions. On the flipside, Runway and other AI companies have been accused of using content without permission to train their public models, something that factors into AI use policies at broadcasters and studios, as well as VFX companies like us.
Loopy
Researchers at Bytedance and Zhejiang University have unveiled Loopy, and it seems like just that, loopy! A while ago, I talked about LivePortrait, an approach to animating still portraits using a video of a face. Loopy drives its facial animation by audio alone, and the results on their project are very impressive!
As with LivePortrait, this kind of approach could be a game-changer for bringing old photos to life or when dubbing films into other languages. If that sounds interesting, check out Flawless AI's TrueSync software being used for dialogue replacement, not only when translating to other languages but also for making films PG by seamlessly removing swearing.
Unreal Engine for Motion Design?
Unreal Engine 5.4’s motion design tools (previously called “Project Avalanche”), have opened up a whole new world of possibilities for working with Unreal Engine. The tools have given the engine capabilities similar to Cinema 4D and After Effects and could see the engine used for more CGI and VFX projects.
I came across these great examples by Arthur Baum and Hussin Khan of these new tools put to use:
These new tools along with Unreal Engine’s use for virtual production on shows like Fallout and House of the Dragon is really showing how Unreal is for much more than just games!
MyWorld
As you may know, Lux Aeterna is part of MyWorld, a UKRI-funded creative technology research programme based in the West of England. Through MyWorld, Lux Aeterna is focusing on machine learning developments and new, innovative toolsets in visual effects.
Being a part of the MyWorld programme has given Lux Aeterna a great opportunity to explore emerging tech even when there are factors that might make those technologies unsuitable for the work we do for our clients. In fact, it helps us better understand what those factors are and our client's technology needs. We also learn loads about broad trends and potential future working practices.
Generated in New York | Runway
When I showed the team the results of Runway’s latest video generation model, Gen-3, there were, unsurprisingly, many questions about what this could mean for visual effects. It didn’t take us long to rattle off a list of things holding this and other video models like Sora back; AI artefacts, low resolution and dynamic range, limited editability, and maybe biggest of all, the myriad legal and ethical issues that surround many generative AI models.
Generative Visual Effects | Runway Academy
That said, there was also a lot of wonder and excitement about the potential capabilities of working with video this way, and what VFX artists could achieve with tools like these in their hands.
Check out my blog post on our AI Acceptable Use Policy here.
Siggraph
With the world’s largest computer graphics conference, Siggraph, having just wrapped up, there’s been a deluge of announcements, tech demos and papers. Lots to catch up on!
One of the great things about Siggraph is that they always make their ‘Real-Time Live!’ show available for folks at home to watch. The show features a number of different artists, engineers and performers showcasing incredible new tech or creative projects, the catch is that everything you see is running in real-time, no time for lengthy renders, inferencing or compiling!
This year the show featured projects covering everything from to 3D avatars to real-time volumetric effects, live music visuals to generative AI-based motion capture. It’s well worth checking out.
Segment Anything 2
Segmentation models can detect and separate out objects or elements within an image, and with Segment Anything 2, Meta have developed a model that can do this at a very high level, quickly and with video! There’s also a demo so everyone can give a go for themselves online!
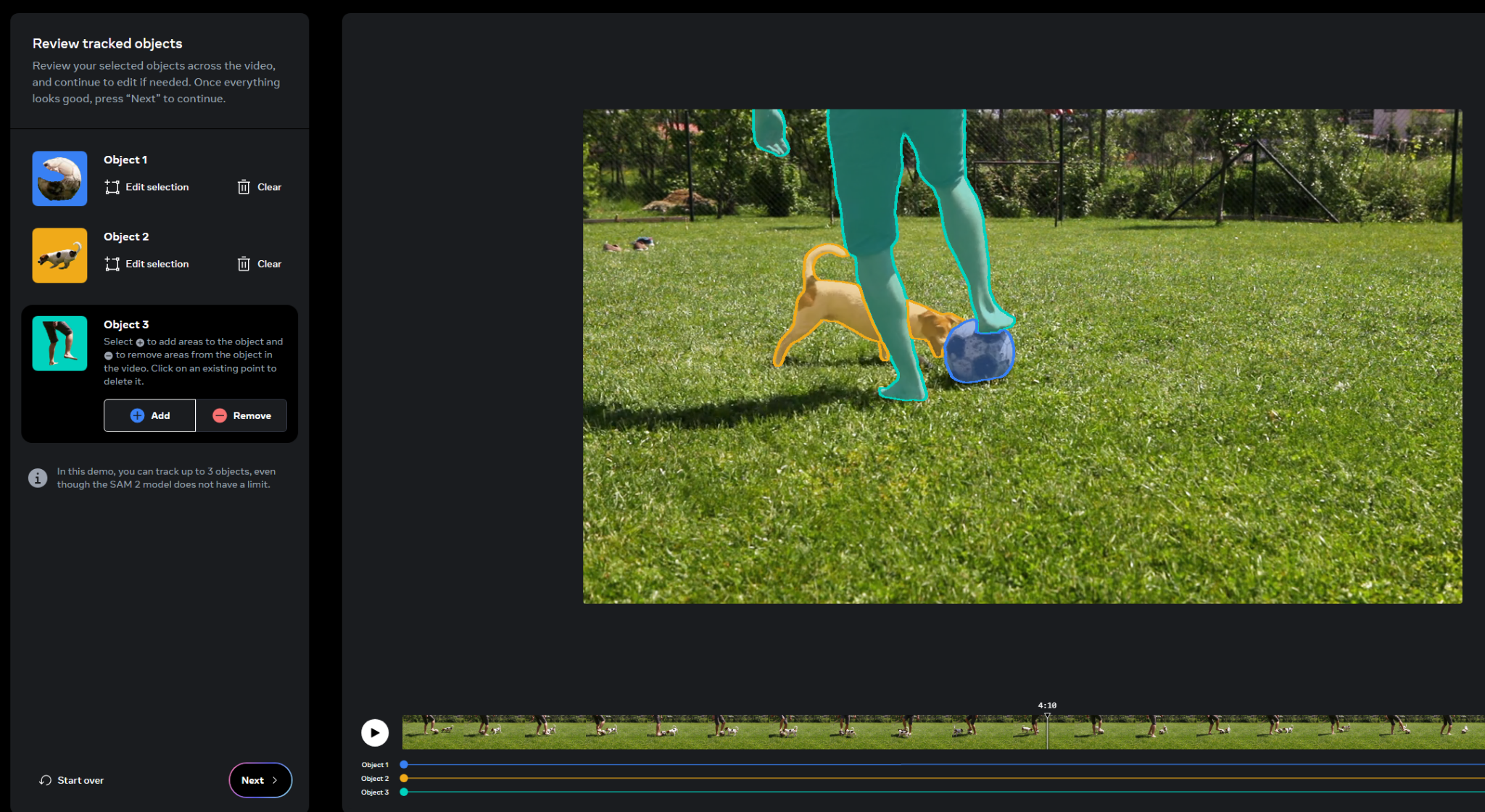
Here we can see three objects within the scene have been segmented, a person, a dog, and a football, and those segmentations are tracked across a video clip. Each segment stays intact even when broken up by another object, like how the dog segment is maintained even when the person’s leg gets in the way.

In the demo Meta provides, you can simply select the areas to segment and apply different effects to them or the background. The model appears to do a decent job at rotoscoping each element out too.
Being able to quickly track and mask different elements within a shot could be a powerful tool for VFX artists, but I could see this model forming part of a wider VFX toolkit.
LivePortrait
We highlighted LivePortrait a couple of weeks ago, a project tackling animating faces in images using driving video, but I thought we’d revisit it because they recently added video animation. This means that LivePortrait can take the facial movements from one video and use them to drive the facial movements in another video.
They’ve also created the option to use a Gradio interface, which makes things a lot easier to navigate than just trying to use a command line interface.
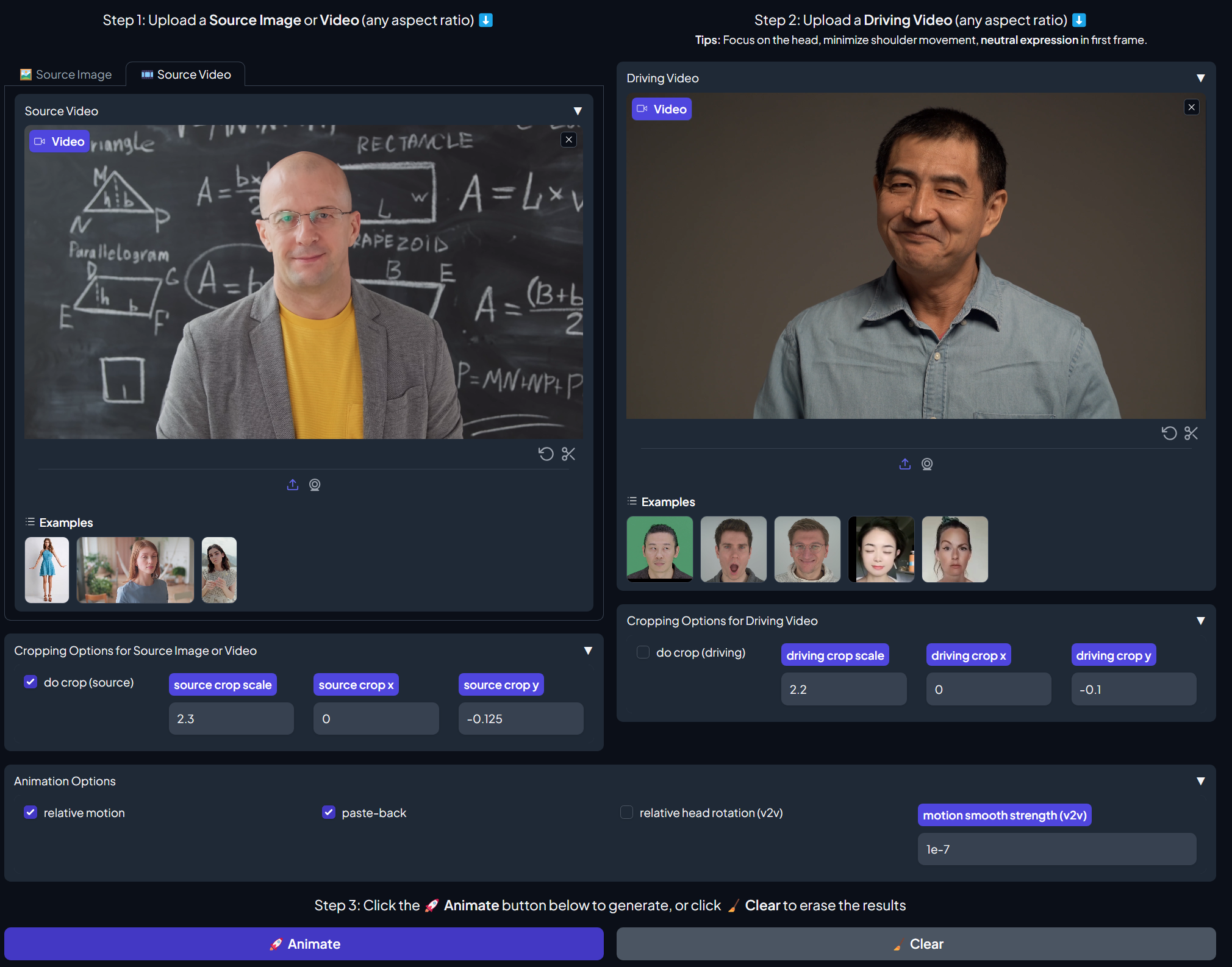
It’s easy to imagine something like this being used for dubbing films one day. In the meantime, I imagine this tech will be appearing in photo apps soon!
Splatfacto-W
A very interesting area of research in the world of volumetric capture is the concept of being able to create 3D representations of scenes from “unconstrained image collections”, i.e. random images of a scene taken at different times of day, with different cameras, etc. Splatfacto-W is an approach for doing just that, and has been implemented in popular NeRF and gaussian splatting software, Nerfstudio.
A potential use case within VFX for such an approach might be producing 3D representations of buildings that no longer exist but for which there’s lots of photographs, or scenes that are awkward to access for a dedicated volumetric capture.
WildGaussians is another approach to this same challenge, so there’s a bit of activity in this area. I’m looking forward to seeing what people make with these, and giving it a go myself!
LivePortrait
Over the past few years, there’s been a series of models that can take an input video of a face and use it to drive an animation of a single still portrait image. LivePortrait is a recent attempt, and while not perfect, the results are pretty good. I’ve used it here to animate a photo of me!
As a studio that often works on historical documentaries, we’re often asked to bring archive material to life. This might involve animating and dimensionalising old black and white photographs. A tool like LivePortrait could be instrumental in animating faces within those photographs.
Of course, the use of such tools would have to be carefully considered, you’re literally puppeting someone’s face after all!
SMERF
SMERF: Streamable Memory Efficient Radiance Fields for Real-Time Large-Scene Exploration
While NERFs (neural radiance fields) were seen as the big thing in volumetric capture and rendering, they drifted into the background when the more performant Gaussian Splatting tech appeared. However, Google has been doing research to make NERFs suitable for real-time applications too.
This is where SMERF comes along. I won't get into the ins and outs of the advancements, but their project site has all the details as well as some great demos you can try in your own web browser. It looks like Google is rolling out this tech to Google Maps to recreate 3D interiors for shops, cafes, etc. I'm interested to see which approach ends up being most applicable to VFX.

Stable Diffusion 3
The big news this week was that Stability.ai have released the weights for the latest iteration of their image generation model, Stable Diffusion 3.
What does this mean? Well, by releasing the weights, Stability is making their Stable Diffusion 3 model available for individuals and organisations to download and use on their own computers. Given the number of tools and extensions that have been developed to support Stable Diffusion, and the ability to “fine-tune” these models with additional training, many image generation platforms and other diffusion-based tools use Stable Diffusion under the hood.
We’ve had extensive experience with Stable Diffusion since its initial release back in August 2022, diving into the power and potential of generative AI through our R&D efforts.
Last year, with the support of Digital Catapult and NVIDIA, we pursued in-depth R&D into Stable Diffusion through the MyWorld Challenge Call. Earlier this year, we worked with digital forensics company CameraForensics to help them explore the capabilities of Stable Diffusion and develop tools to aid in the detection of generated images.
So what’s new with Stable Diffusion 3? Stability claims its new model can better interpret prompts, better reproduce text and typography, as well as overall image quality and performance improvements. Time will tell if Stable Diffusion 3 is as popular as previous versions
Due to the way models like Stable Diffusion have been trained on images scraped from the internet, there are many legal and ethical question marks over the use of it and other generative AI models in a professional commercial environment. As such, Lux Aeterna currently does not use these generative AI models in the creation and delivery of our VFX work. You can find out more about our AI use policy here.
Estimation Models
Today I’m showing how powerful estimation models can change how we work with images and video by giving us accurate approximations of aspects of image such as depth and normals.
Depth Anything
Depth Anything is a monocular depth estimation model developed by researchers at HKU, TikTok, CUHK and ZJU. This model creates a depth representation of an image based on an estimation of how near or far away objects in the image are from the camera. These kinds of depth images can be helpful in many kinds of visual effects work, like adding haze and fog to a scene, or dimensionalising archive photographs.

SwitchLight
SwitchLight takes this concept of estimating aspects of a given image and by utilising multiple models built for different estimations, creates a whole toolkit for relighting video. As you can imagine, these sorts of tools could be invaluable to compositors that often have to take things like green screen footage and make it work in a different scene.
SwitchLight: Production Ready AI Lighting (CVPR 2024)